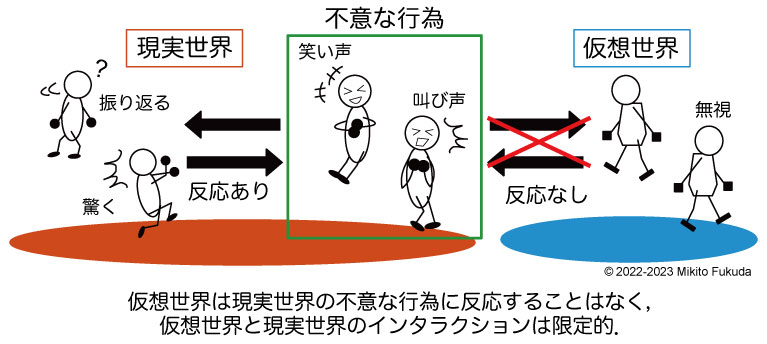
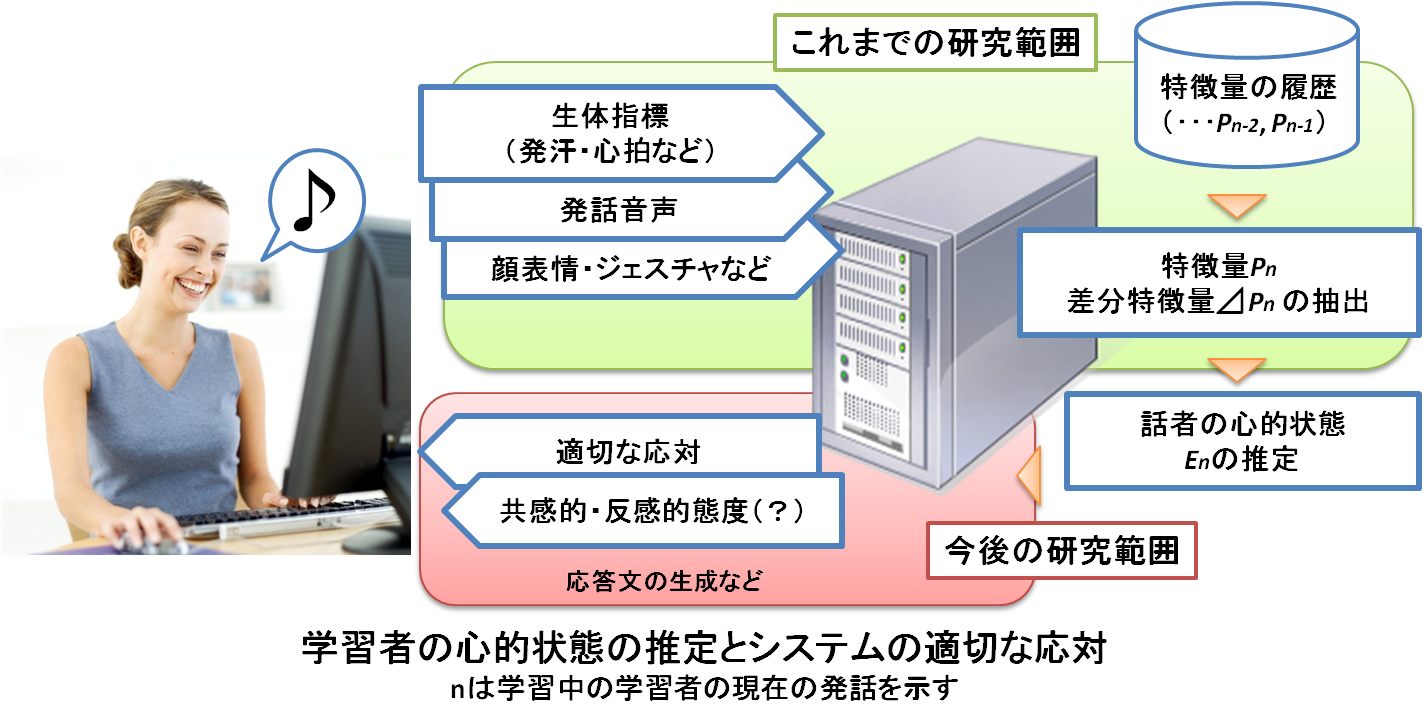
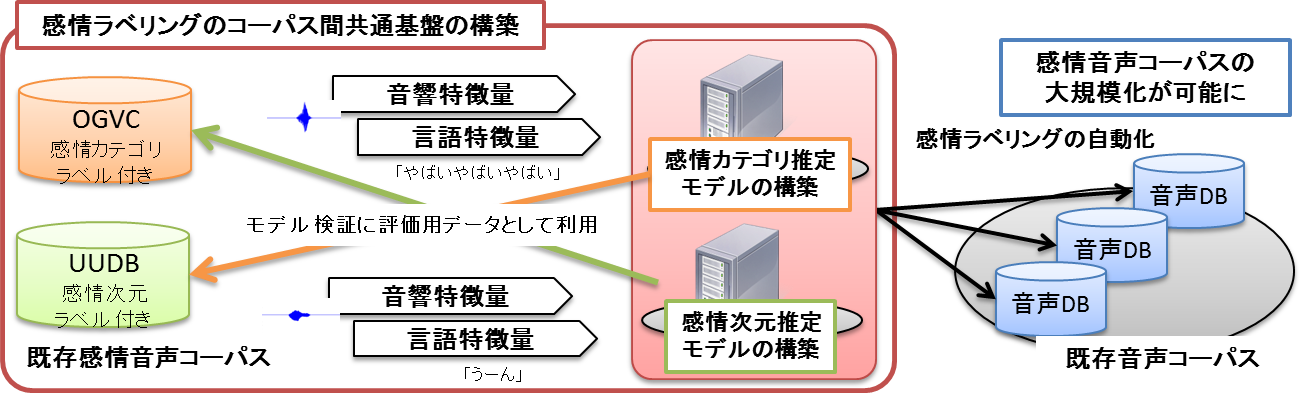
千葉工業大学情報科学部情報工学科の多感覚情動情報処理研究室(有本研究室)です。
人間のマルチモーダルな情報から感情とコミュニケーションを計算可能にする研究を行っています。
What’s new?
2025-11-11
new
人工知能学会 言語・音声理解と対話処理研究会(SLUD)第105回研究会「第16回対話システムシンポジウム」にてM1の木澤妃名子さんが若手萌芽賞を受賞しました。おめでとうございます!
2025-08-24
new
The 17th Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA2025)にてM2の倉澤瑞さんの論文”Effectiveness of streaming ASR for real-time laughter and screaming detection”が採択されました。
2025-06-20
The 13th International Conference on Affective Computing and Intelligent Interaction (ACII 2025)にM1の木澤妃名子さんの論文”Physiological analysis of the effect of laughter contagion on speakers’ mental states in gaming environment”が採択されました。
2025-06-12
音学シンポジウム2025(第143回音楽情報科学・第156回音声言語情報処理合同研究発表会)にてM2の倉澤瑞さんが研究発表を行います。
2025-05-19
Interspeech2025にM2の瀬戸口遼さんの論文”Assessment of the synthetic quality and controllability of laughing onset in speech-laugh synthesis”が採択されました。瀬戸口さんは2度目のInterspeechでの発表となります。
2025-02-14
人工知能学会言語・音声理解と対話処理研究会(SIG-SLUD)第103回研究会にてB4の木澤妃名子さんと黛大誠さんが研究発表を行います。
2025-01-23
日本音響学会音声研究会と電子情報通信学会ヴァーバルノンヴァーバルコミュニケーション研究会の共催研究会にてB4の佐藤亮太さんが研究発表を行います。
2025-01-17
日本音響学会2025年春季研究発表会にてM2の白鳥恵大さんとM1の瀬戸口遼さんが研究発表を行います。
2024-12-21
電子情報通信学会ヴァーバルノンヴァーバルコミュニケーション研究会とヒューマンコミュニケーション基礎研究会の共催研究会
にてB4の木澤妃名子さんが発表した研究が2024年度ヒューマンコミュニケーション基礎(HCS)研究会賞を受賞しました。おめでとうございます!
にてB4の木澤妃名子さんが発表した研究が2024年度ヒューマンコミュニケーション基礎(HCS)研究会賞を受賞しました。おめでとうございます!
2024-11-16
情報処理学会 第262回自然言語処理・第154回音声言語情報処理合同研究発表会でM2の白鳥さんが研究発表を行います。
2024-11-04
第29回公益財団法人栢森情報科学振興財団,研究助成事業に「笑い開始を制御可能とするspeech-laugh合成」が採択されました。
2024-10-29
Acoustical Science and Technologyに論文”A comparison between crowdsourcing and in-person listening tests on emotion rating for spontaneous screaming and shouting”が採択されました。本論文の内容は卒業生の大石暖さん(2024卒)と大久保港さん(2023卒)の研究です。
2024-08-01
電子情報通信学会ヴァーバルノンヴァーバルコミュニケーション研究会とヒューマンコミュニケーション基礎研究会の共催研究会でB4の木澤さんが研究発表を行います。
以前のお知らせ
2024-06-04
Interspeech2024にM1の瀬戸口さんの論文”Acoustical analysis of the initial phones in speech-laugh”が採択されました。
2024-04-23
人工知能学会言語・音声理解と対話処理研究会(SIG-SLUD)第100回研究会にて卒業生の岩立直也さんが発表した研究が2023年度研究会優秀賞を受賞しました。おめでとうございます!
2024-02-04
人工知能学会言語・音声理解と対話処理研究会(SIG-SLUD)第100回研究会にてB4の岩立直也さんが研究発表を行います。
2024-01-31
日本音響学会音声研究会と電子情報通信学会ヴァーバルノンヴァーバルコミュニケーション研究会の共催研究会にてB4の飯田真広さんとM2の松田匠翔さんが研究発表を行います。
2024-01-11
日本音響学会2024年春季研究発表会にてB4の瀬戸口遼さんと大石暖さんが研究発表を行います。大石さんの研究は卒業生の大久保さん(2023卒)との共同研究です。
2023-12-29
Acoustical Science and Technology にM2の松田さんの論文 “Acoustic differences between laughter and screams in spontaneous dialog” が採択されました。
2023-12-25
日本音響学会2023年秋季研究発表会にてM2の松田匠翔さんの研究が学生優秀発表賞を受賞しました。おめでとうございます!
2023-12-14
人工知能学会言語・音声理解と対話処理研究会(SLUD)第99回研究会「第14回対話システムシンポジウム」にてB4の倉澤瑞さんと卒業生の福田樹人さん(2023院卒)の研究が若手萌芽賞を受賞しました。おめでとうございます!
2023-11-15
第14回対話システムシンポジウムにてB4の倉澤瑞さんが研究発表を行います。倉澤さんの研究は卒業生の福田さん(2023院卒)との共同研究です。
2023-11-03
卒業研究中間発表会でB4の岩立さんがプレゼンテーション賞を取りました。
2023-07-31
日本音響学会2023年秋季研究発表会にてM2の松田匠翔さん,B4の瀬戸口遼さんが研究発表を行います。
2023-05-24
音学シンポジウム2023にてM2の松田さんとM1の白鳥さんが研究発表を行います。
2023-05-17
Interspeech2023にM2の松田さんの論文”Detection of laughter and screaming using the attention and CTC models”が採択されました。
2023-01-23
日本音響学会2023年春季研究発表会にてB4の白鳥恵大さんが研究発表を行います。
2022-09-23
Acoustical Science and Technologyに論文“Phonetic analysis on speech-laugh occurrence in a spontaneous gaming dialog”が採択されました。
2022-09-08
Asia Pacific Signal and Information Processing Association Annual Summit and Conference 2022 (APSIPA ASC 2022)にM2の福田樹人さんの論文“Physiological Study on the Effect of Game Events in Response to Player’s Laughter”が採択されました。
2022-08-25
人工知能学会言語・音声理解と対話処理研究会(SIG-SLUD)にてM2の福田樹人さんが研究発表を行います。
2022-08-17
言語資源ワークショップ2022にてB4の白鳥恵大さんが研究発表を行います。また,B4の真弓花さんの研究を有本が代理発表します。
2022-07-21
日本音響学会2022年秋季研究発表会にてM1の松田匠翔さん,B4の大久保湊さんが研究発表を行います。大久保さんの研究は卒業生の井岸渉さん(2020卒)との共同研究です。
2022-07-21
中山隼雄科学技術文化財団の設立30周年記念研究助成に「感情情報を利用した表現豊かな笑い声・叫び声合成」が採択されました。
2022-06-30
日本学術振興会 (JSPS) 2022度科学研究費補助金, 挑戦的研究(萌芽)に「Speech-laughの発生機序の解明(22K18477)」が採択されました。
2022-04-25
感情次元情報を入力とした笑い声合成を追加しました。実際に合成した笑い声のサンプルを聞くことができます。
2022-04-01
今年度より有本が国立国語研究所共同研究プロジェクト「多世代会話コーパスに基づく話し言葉の総合的研究」に共同研究員として参画します。
2022-01-22
Speech Prosody 2022にB4の松田匠翔さんの論文”Acoustic discriminability of unconscious laughter and scream during game-play”が採択されました。
2022-01-12
情報処理学会論文誌に論文「自然で表現豊かな笑い声合成に向けた感情情報からの笑い声の構成要素決定法」が採択されました。卒業生の今西利於さんの研究テーマです。
2022-01-10
日本音響学会2022年春季研究発表会にてB4の土井敦也さん,松田匠翔さんが研究発表を行います。
2021-11-25
電子情報通信学会HCGシンポジウム2021にてM1の福田樹人さんが研究発表を行います。
2021-07-26
日本音響学会2021年秋季研究発表会にてB4の松田匠翔さんが研究発表を行います。
2020-12-17
電子情報通信学会HCGシンポジウム2020で発表した”現実世界における無意識な感情表出に対して生成されるゲームイベントの効果”の研究が特集テーマセッション賞を受賞しました。
2020-09-11
日本音響学会2020年秋季研究発表会にてB4の今西利於さんが研究発表を行います。
2020-03-09
日本音響学会2020年春季研究発表会にてB4のKhoo Yu Yenさん,金子裕亮さん,小山俊樹さんが研究発表を行います。
2019-07-12
日本音響学会2019年秋季研究発表会にてB4のKhoo Yu Yenさんが研究発表を行います。
2019-06-17
Interspeech2019に共著論文”Conversational and Social Laughter Synthesis with WaveNet”が採択されました。
2019-05-18
2019年研究室対抗フットサル大会を追加しました。
2018-12-17
さくらサイエンスプログラムを追加しました。